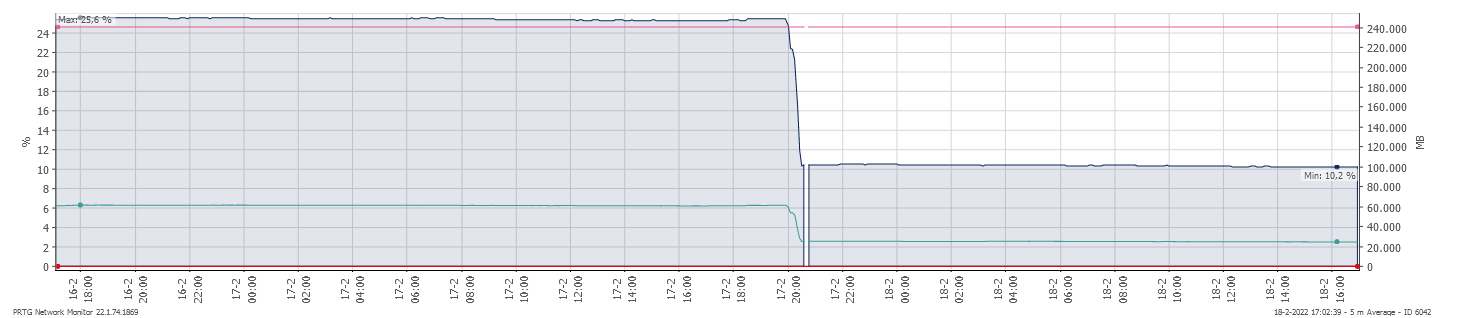
I have a customer with about 3500 users that uses Connections 6.5 CR1 and Component pack. I noticed that every time the Kubernetes cluster would get into trouble (usually after a Linux admin without warning rebooted multiple worker nodes), the size of the Elasticsearch index grows. This picture shows the sudden drop in available disk space, caused by such outage.
When I look in the index directory (/pv-connections/esdata-1/data/nodes/0/indices) I see this:
drwx------. 6 4096 Feb 17 21:35 DSdiksRVQBqy6S6rve7Dsw
drwx------. 7 4096 Feb 17 21:34 MlUXC_gGQAyPKmMuF6WpXQ
drwx------. 11 4096 Feb 17 21:34 msw46HE8QmSGRorcTGrKzQ
drwx------. 6 4096 Feb 17 21:35 VRBYQgZVTU2UpN49Ghs-Bw
drwx------. 7 4096 Feb 17 21:35 wctsgAY7T32B_l3fSeNLhA
drwx------. 6 4096 Feb 17 21:35 WSTxDGLhTeyC-UTJuGyJBQ
drwx------. 6 4096 Feb 17 21:34 z2FXcVedQLumS6LFxea32Q
drwx------. 7 4096 Feb 17 21:34 ZqrQSHHaTj-XIU2obr7Lyg
drwx------. 6 4096 Feb 17 21:34 zTylkst2TXymyYrArExykQ
drwx------. 6 4096 Feb 17 21:35 zzJ9nxZZRaGEa2bwN8Bmlw
drwx------. 7 4096 Feb 17 21:34 ZZYQu3XhTe-8moV088VKQg
Please, note that the last modified time of the directories corresponds to the date/time of the crash. The index currently takes 37 GB x 3 (directory per pod) = 111 GB. Something is going very wrong here.
Has anyone seen this in their environment and if so, how did you solve it?